 I have received a number of requests about the tools and methods used to complete the gap analysis steps from earlier posts in the series How to Build a Roadmap. In this series I have discussed the specific steps required to develop a well thought out road map where one of the key tasks was conducting a gap analysis exercise. Understanding the limits of a medium like this I have posted this update to explore the questions in a little more detail. Believe this will be extremely useful to anyone building a meaningful road map. The internet is full of simply awful templates and tools which range from the downright silly to extremely dangerous in their simple assumptions where there is no attempt to quantify results. Even more distressing is lack of understanding of how to use and leverage the best data sources you already have – the professionals within your own organization. Save yourself some time and read on.
I have received a number of requests about the tools and methods used to complete the gap analysis steps from earlier posts in the series How to Build a Roadmap. In this series I have discussed the specific steps required to develop a well thought out road map where one of the key tasks was conducting a gap analysis exercise. Understanding the limits of a medium like this I have posted this update to explore the questions in a little more detail. Believe this will be extremely useful to anyone building a meaningful road map. The internet is full of simply awful templates and tools which range from the downright silly to extremely dangerous in their simple assumptions where there is no attempt to quantify results. Even more distressing is lack of understanding of how to use and leverage the best data sources you already have – the professionals within your own organization. Save yourself some time and read on.
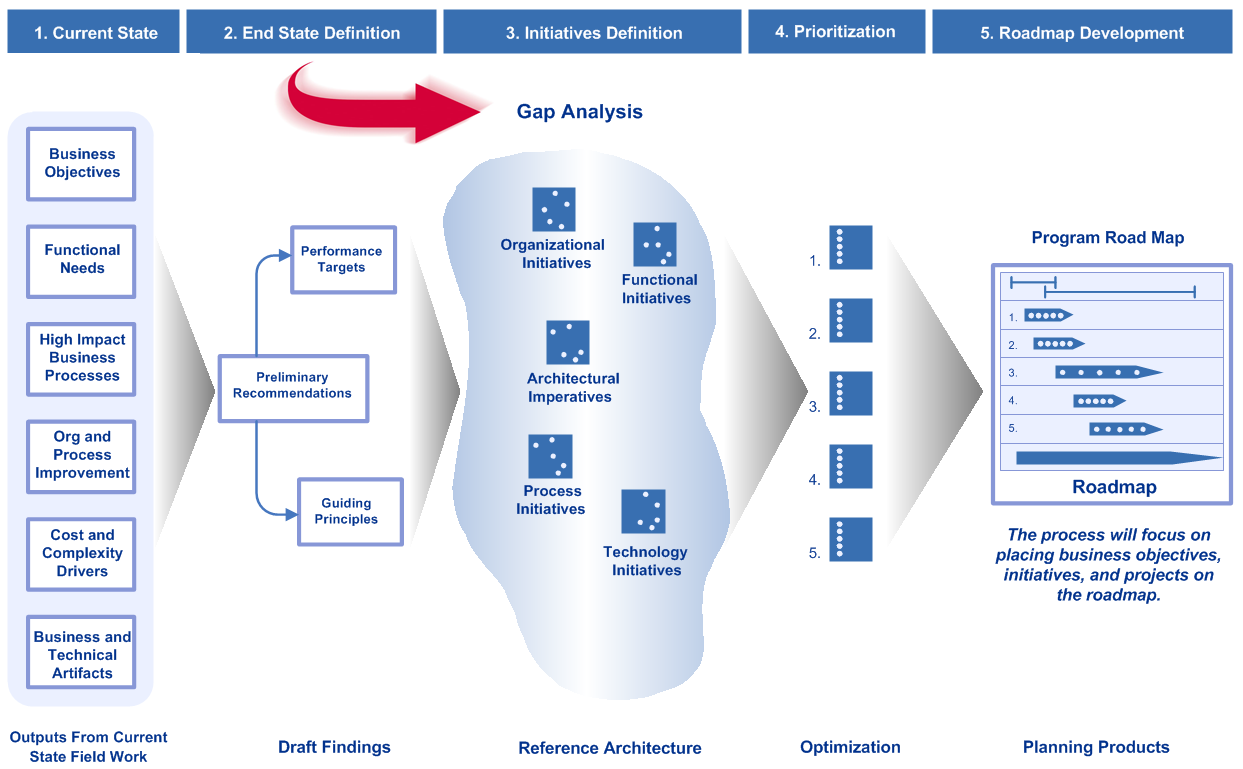
Recall the road map development identified specific actions using an overall pattern ALL road maps should follow. The steps required to complete this work:
- Develop a clear and unambiguous understanding of the current state
- Define the desired end state
- Conduct a Gap Analysis exercise
- Prioritize the findings from the Gap Analysis exercise into a series of gap closure strategies
- Discover the optimum sequence of actions (recognizing predecessor – successor relationships)
- Develop and Publish the Road Map
The Gap Analysis step discussed how to develop a robust analytic to find any significant shortcomings between the current and desired end states. We use these findings to begin develop strategy alternatives (and related initiatives) to address what has been uncovered. Our intent is to identify and quantify the difference (delta) from where we are to what we aspire to become. This exercise is critical to find what needs to be accomplished. The gap analysis leads to a well-organized set of alternatives and practical strategies we can use to complete the remaining work. You can review the full post here.
Gap Analysis
The goal? Seek a quick and structured way to define actionable activities to be reviewed and approved by all stakeholders. We would like focus on the important actions requiring attention. This includes identifying a set of related organizational, functional, process, and technology initiatives needed. The gap closure recommendations give a clear line of sight back to what needs to be accomplished to close the “delta” or gaps uncovered in the analysis.
What is needed than is a consistent, repeatable way to evaluate quickly where an organization is, where they want to go, and the level of effort needed to accomplish their goals with some precision. In short the delta between current and desired state is uncovered, quantified, and ready for a meaningful road map effort based on factual findings supported by real evidence captured in the field. Performing a successful gap analysis begins with defining what you are analyzing which could be processes, products, a region, or an entire organization. Even at the overall organizational level, knowing what aspect you are analyzing is crucial to find and understand the intent and findings of the effort. Quickly focusing at the desired level of detail means we can now:
- Know where to go; what really needs attention
- Pinpoint opportunity…quickly.
- Uncover what is preventing or holding back an important initiative
- Know what to do – and in what suggested order
This is where problem solving using some quick management diagnostic tools can be used across a variety of challenges met when developing a road map. Using these tools to perform the gap analysis delivers quick distinctive results and provides the key data and actionable insight needed to develop a meaningful road map. This method (and the tools) can be used to:
- evaluate capability using a generally accepted maturity model specific to the business,
- focus on a specific subject area or domain; Master Data Management or Business Intelligence are two examples were known proven practice can be used as starting point to support the findings compiled,
- assess the readiness of an important program or evaluate why it is in trouble,
- evaluate and uncover root cause issues with a struggling project,
- detect and measure what requires immediate attention by uncovering weaknesses where proven practice has not been followed or adopted.
Quick Management diagnostic tools
The tool set I use follows the same general pattern and structure, only the content or values differ based on how focused the effort is and what is needed to complete the work successfully. The questions, responses, and data points gathered and compiled are usually organized in a structured taxonomy of topics. See the earlier post (Define End State) for more on this. The key is using the same engine to tabulate values based on responses that can range from zero (0 – Never or No) to five (5 – Always or Yes). Of course you can customize the responses. In fact I have done this with a Program Readiness Assessment and BigData Analytics tool. The real point is to quantify the responses received. The engine component takes the results builds a summary, and produces accompanying tabs where radar graphs plots present the Framework, Topic, Lookup, # Questions, Current State Scores, Desired End State Scores, and common statistical results within each grouping. The tool can be extended to include MS Word document templates which then link to the findings worksheet and grabs the values and charts produced to assemble the draft document ready for further editing and interpretation. If all this sounds confusing, a couple of examples may be helpful.
Using the Data Maturity Model (CMMI) to Evaluate Capability
The Data Maturity Model (DMM) was developed using the principles and structure of CMMI Institute’s Capability Maturity Model Integration (CMMI)—a proven approach to performance improvement and the gold standard for software and systems development for more than 20 years. The DMM model helps organizations become more proficient in managing critical data assets to improve operations, enable analytics and gain competitive advantage.
Using this body of knowledge and a library of source questions we can elicit current state and desired end state responses using a simple survey. This can be conducted online, in workshops, or traditional interviews as needed. The responses are compiled and grouped to evaluate the gap closure opportunities for an organization wishing to improve their data management practices by identifying and taking action to address shortcoming or weaknesses identified. The framework and topic structure of the 142 questions are organized to match the DMM model. 
Looking closer we find the nine (9) questions used to elicit responses related to Business Glossaries within the Data Governance topic.
1) Is there a policy mandating use and reference to the business glossary?
2) How are organization-wide business terms, definitions, and corresponding metadata created, approved, verified, and managed?
3) Is the business glossary promulgated and made accessible to all stakeholders?
4) Are business terms referenced as the first step in the design of application data stores and repositories?
5) Does the organization perform cross-referencing and mapping of business-specific terms (synonyms, business unit glossaries, logical attributes, physical data elements, etc.) to standardized business terms?
6) How is the organization’s business glossary enhanced and maintained to reflect changes and additions?
7) What role does data governance perform in creating, approving, managing, and updating business terms?
8) Is a compliance process implemented to make sure that business units and projects are correctly applying business terms?
9) Does the organization use a defined process for stakeholders to give feedback about business terms?
Responses are expected to include or more of the following values describing current state practice and what the respondent believes is a desired end state. These can simply be a placed on a scale where the following values are recorded for both current and desired outcomes.
Responses
0 – Never or No
1 – Awareness
2 – Occasionally
3 – Often
4 – Usually
5 – Always or Yes
In this example note how the relatively simple response can be mapped directly into the scoring description and perspective the DMM follows.
0 – No evidence of processes performed or unknown response.
1 – Performed Processes are performed ad hoc, primarily at the project level. Processes are typically not applied across business areas. Process discipline is primarily reactive; for example, data quality processes emphasize repair over prevention. Foundational improvements may exist, but improvements are not yet extended within the organization or maintained. Goal: Data is managed as a requirement for the implementation of projects.
2 – Managed Processes are planned and executed in accordance with policy; employ skilled people with adequate resources to produce controlled outputs; involve relevant stakeholders; are monitored and controlled and evaluated for adherence to the defined process. Goal: There is awareness of the importance of managing data as a critical infrastructure asset.
3 – Defined Set of standard processes is employed and consistently followed. Processes to meet specific needs are tailored from the set of standard processes according to the organization’s guidelines. Goal: Data is treated at the organizational level as critical for successful mission performance.
4 – Measured Process metrics have been defined and are used for data management. These include management of variance, prediction, and analysis using statistical and other quantitative techniques. Process performance is managed across the life of the process. Goal: Data is treated as a source of competitive advantage.
5 – Optimized Process performance is optimized through applying Level 4 analysis for target identification of improvement opportunities. Best practices are shared with peers and industry. Goal: Data is critical for survival in a dynamic and competitive market.
The key here is capturing both current state (what is being performed now) and the desired end state capability using this tool. The difference or delta between the two values now becomes a data set we can use analytic tools to reveal where the greatest challenges are. In this example the clear gaps (represented in orange and red visual cues) show where we should focus our immediate attention and call for further investigation. Yellow shaded topics are less urgent. All green shaded topics don’t need the same rigor when addressing the actions needed in the road map developed in later stages.

Specific Subject Area – Master Data Management Assessment
In this example we can extend and focus on Master Data Management using the same principles and structure of CMMI Institute’s Capability Maturity Model Integration (CMMI), adding proven practice in the Master Data Management domain. Note the framework and topic structure is far more focused to match the MDM model framework. And the library of survey questions used here (225 questions) are far more detailed and now very much focused on Master Data Management.

Using the same scoring engine we have captured both current state (what is being performed now) and the desired end state capability using this tool. The difference or delta between the two values now becomes a data set we can use analytic tools to reveal where the greatest challenges are. The clear gaps (represented in orange and red visual cues) pop off the page when the size and relative distance from desired or needed and current practice is measured. Now there is a good idea of what needs to be addressed in the road map developed in later stages.

This is a quick way to summarize our findings and give valuable clues and direction for further investigation. We can then focus on specific problem areas using detailed schedules based on the field work to date. Based on the gaps uncovered at the higher level summary (Current vs. Desired End State) further investigation should be performed by a professional with deep subject matter expertise and intimate knowledge of generally accepted proven practice. Using the same data set we can now begin to use an interactive exploration tools to uncover significant patterns and reveal further insight.

Results
I hope this has helped readers who have asked about how to develop and use gap analysis tools to find quickly what significant delta items (the difference between current and desired states) demand further attention. I think you can see this is valuable way to quickly gather, compile field work, and capture a fairly comprehensive view of the gaps uncovered between the current and desired end state of the subject in question. This method and set of tools can be used in a variety of management challenges across the business both big and small. Armed with this information we can now go ahead to step four (4) and begin to prioritize the findings from the Gap Analysis exercise into a series of gap closure strategies.
This is an invaluable way to assemble and discover the best sequence of actions (recognizing predecessor – successor relationships) as we move to developing the road map. This difference (delta) between these two (current and desired end state) is the basis for our road map. I hope this has answered many of the questions about step three (3) Conduct a Gap Analysis exercise. This is not the only way to do this, but has become the most consistent and repeatable methods I’m aware of to perform a gap analysis quickly in my practice.
If you enjoyed this post, please share with anyone who may help from reading it. And don’t forget to click the follow button to be sure you don’t miss future posts. Planning on compiling all the materials and tools used in this series in one place, still unsure of what form and content would be the best for your professional use.Please take a few minutes and let me know what form and format you would find most valuable.
Suggested content for premium subscribers:
- Topic Area Models (for use with Mind Jet – see https://www.mindjet.com/ for more)
- Master Data Management Gap Analysis Assessment
- Data Maturity Management Capability Assessment
- Analytic Practice Gap Analysis Assessment
- Big Data Analytic Gap Analysis Assessment
- Program Gap Analysis Assessment
- Program Readiness Assessment
- Project Gap Analysis Assessment
- Enterprise Analytic Mind Map
- Reference Library with Supporting Documents


















 This post is part of a larger series to provide a detailed set of steps you can take to unlock breakthrough results in Big Data Analytics. The simple use case used to illustrate this method will address the perplexing management challenge of platform and tool optimization. This step is used to identify the types and nature of the operating models used within the analytic community. I’m using a proven approach for solving platform and tool optimization in the same manner that proven practice suggests every analytic decision be made. Here we are simply using an organizing principle to group and categorize our findings in what can quickly become a bewildering experience (much like herding cats) in its complexity and nuance.
This post is part of a larger series to provide a detailed set of steps you can take to unlock breakthrough results in Big Data Analytics. The simple use case used to illustrate this method will address the perplexing management challenge of platform and tool optimization. This step is used to identify the types and nature of the operating models used within the analytic community. I’m using a proven approach for solving platform and tool optimization in the same manner that proven practice suggests every analytic decision be made. Here we are simply using an organizing principle to group and categorize our findings in what can quickly become a bewildering experience (much like herding cats) in its complexity and nuance. accomplish its function. An operating model breaks this system into components, showing how each works together. It helps us understand the whole. In our case we are going to focus on the analytic community and use this understanding to evaluate fit when making changes to ensure the enabling models will still work after the recommended optimization is called for. Thanks to Gartner who published
accomplish its function. An operating model breaks this system into components, showing how each works together. It helps us understand the whole. In our case we are going to focus on the analytic community and use this understanding to evaluate fit when making changes to ensure the enabling models will still work after the recommended optimization is called for. Thanks to Gartner who published 
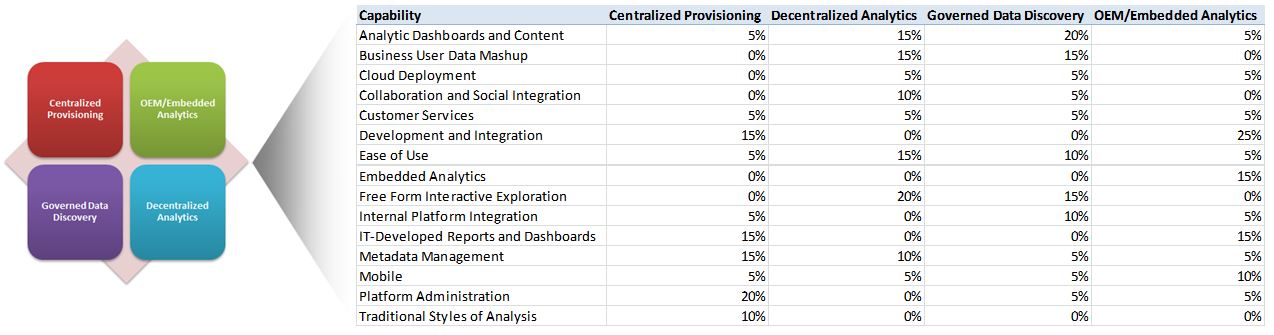
 The classic model used for years in delivery of what has been referred to as business intelligence. Typically we would find tight management controls to push through centralized strategy and efficiency, usually at a high cost. Tightly managed processes for collecting and cleaning data before consumption can be found in the classic patterns associated with Extract, Transform, and Load operations into a data warehouse or mart. Most often characterized by formal processes where a developer or specialists collects business requirements from the users and then creates sanctioned reports and dashboards for them on trusted data. Centralized provisioning enables an information consumer to access their
The classic model used for years in delivery of what has been referred to as business intelligence. Typically we would find tight management controls to push through centralized strategy and efficiency, usually at a high cost. Tightly managed processes for collecting and cleaning data before consumption can be found in the classic patterns associated with Extract, Transform, and Load operations into a data warehouse or mart. Most often characterized by formal processes where a developer or specialists collects business requirements from the users and then creates sanctioned reports and dashboards for them on trusted data. Centralized provisioning enables an information consumer to access their  The opposite of centralized provisioning, this model or loose confederation encourages local optimization and entrepreneurial drive. Look for a community that rapidly and interactively explores trends or detects patterns in data sets often from multiple sources to identify opportunities or risks with minimal support from the IT development community. Interactivity and discovery in this model is NOT limited to what is designed in by the content authors we find in the Centralized Provisioning model. The users are the content authors. Users of platforms and tools that excel at the decentralized analytics model can explore data using highly interactive descriptive analytic (“what happened” or “what is happening”) or diagnostic analytic (“Why did something happen?”, “Where are areas of opportunity or risk?”, and “What if?”). Because of embedded advanced analytic functions offered by many vendors, users can extend their analysis to some advanced descriptive analysis (for example, clustering, segmenting and correlations) and to a basic level of predictive analytic (for example, forecasting and trends). They can also prepare their own data for analysis, reducing their reliance on IT and improving time to insight. As decentralized analytics becomes more pervasive, the risk of multiple sources of the truth and information governance itself becomes a real challenge. Six of fourteen most important capabilities important capabilities needed in this model would include:
The opposite of centralized provisioning, this model or loose confederation encourages local optimization and entrepreneurial drive. Look for a community that rapidly and interactively explores trends or detects patterns in data sets often from multiple sources to identify opportunities or risks with minimal support from the IT development community. Interactivity and discovery in this model is NOT limited to what is designed in by the content authors we find in the Centralized Provisioning model. The users are the content authors. Users of platforms and tools that excel at the decentralized analytics model can explore data using highly interactive descriptive analytic (“what happened” or “what is happening”) or diagnostic analytic (“Why did something happen?”, “Where are areas of opportunity or risk?”, and “What if?”). Because of embedded advanced analytic functions offered by many vendors, users can extend their analysis to some advanced descriptive analysis (for example, clustering, segmenting and correlations) and to a basic level of predictive analytic (for example, forecasting and trends). They can also prepare their own data for analysis, reducing their reliance on IT and improving time to insight. As decentralized analytics becomes more pervasive, the risk of multiple sources of the truth and information governance itself becomes a real challenge. Six of fourteen most important capabilities important capabilities needed in this model would include: A hybrid of centralized and decentralized this model is best characterized by offering freedom within a framework to enhance transparency and effectiveness. This model features business users’ ability to prepare and combine data, explore and interact visually with this data to enable discovery to be deployed and managed across the enterprise. With the success of data discovery tools in driving business value, there is an increasing demand to use data discovery capabilities for a broader range of analysis and an expanded set of users than previously addressed by traditional reporting and dashboards. Governed data discovery enables users to access, blend and prepare data, then visually explore, find and share patterns with minimal IT support using their own technical and statistical skills. At the same time, this model must also satisfy enterprise requirements for business-user-generated model standards, data reuse and governance. In particular, users should be able to reuse sanctioned and approved business-user-created data or data sets, derived relationships, derived business models, derived KPIs, and metrics that support analyses.
A hybrid of centralized and decentralized this model is best characterized by offering freedom within a framework to enhance transparency and effectiveness. This model features business users’ ability to prepare and combine data, explore and interact visually with this data to enable discovery to be deployed and managed across the enterprise. With the success of data discovery tools in driving business value, there is an increasing demand to use data discovery capabilities for a broader range of analysis and an expanded set of users than previously addressed by traditional reporting and dashboards. Governed data discovery enables users to access, blend and prepare data, then visually explore, find and share patterns with minimal IT support using their own technical and statistical skills. At the same time, this model must also satisfy enterprise requirements for business-user-generated model standards, data reuse and governance. In particular, users should be able to reuse sanctioned and approved business-user-created data or data sets, derived relationships, derived business models, derived KPIs, and metrics that support analyses. In this model analytics (decisions, business rules, and processes) are integrated into the organization to capture economies of scale and consistency across planning, operations, and customer experience. Most typically found where developers are using software development kits (SDKs) and related APIs to include advanced analytics and statistical functions within application products. These capabilities are used to create and modify analytic content, visualizations and applications and embed them into a business process, application or portal. Analytic functions can reside outside the application, reusing the infrastructure but should be easily and seamlessly accessible from inside the application, without forcing users to switch between systems. The ability to integrate analytics with the application architecture will enable the analytic community to choose where in the business process the analytics should be embedded. On example of a critical capability for embedding advanced analytics would include consuming a SAS/R or PMML model to create advanced models embedded in dashboards, reports or data discovery views. Six of the fourteen most important capabilities needed in this model would include:
In this model analytics (decisions, business rules, and processes) are integrated into the organization to capture economies of scale and consistency across planning, operations, and customer experience. Most typically found where developers are using software development kits (SDKs) and related APIs to include advanced analytics and statistical functions within application products. These capabilities are used to create and modify analytic content, visualizations and applications and embed them into a business process, application or portal. Analytic functions can reside outside the application, reusing the infrastructure but should be easily and seamlessly accessible from inside the application, without forcing users to switch between systems. The ability to integrate analytics with the application architecture will enable the analytic community to choose where in the business process the analytics should be embedded. On example of a critical capability for embedding advanced analytics would include consuming a SAS/R or PMML model to create advanced models embedded in dashboards, reports or data discovery views. Six of the fourteen most important capabilities needed in this model would include:
